Introduction
The study of human affective behaviour requires capturing emotion expressions in diverse, naturalistic environments (in the wild) from different modalities, such as video, audio and text. Currently, there is a number of commercial and open-source tools which analyse human emotions in video, audio and text. However, none of these tools is currently capable of combining state-of-the-art, open-source, and free solutions into one single workflow. For this reason, we developed the Multimodal Emotion eXpression Capture Amsterdam (MEXCA) pipeline.
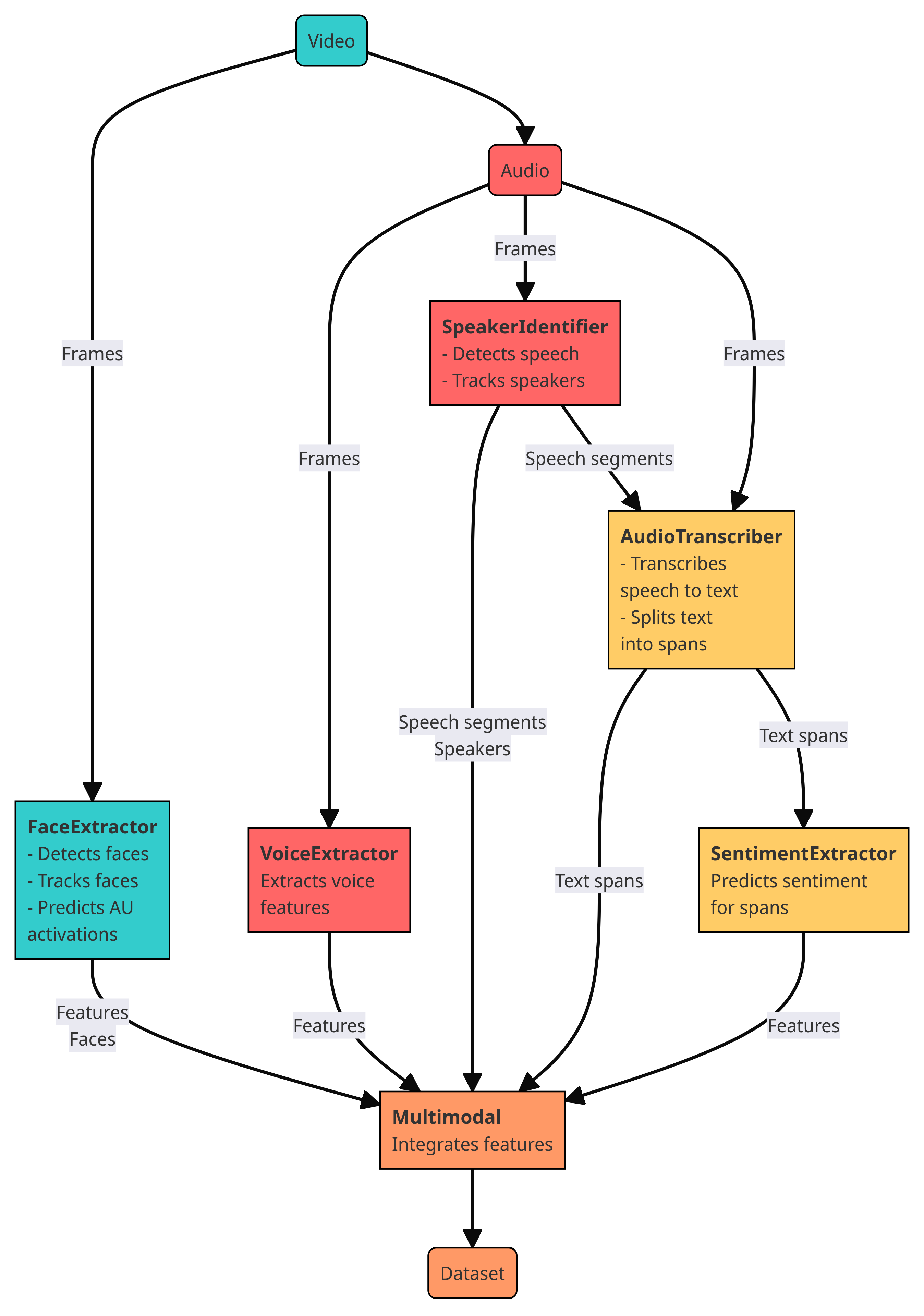
mexca is an easy-to-use, customizable Python package implementing the MEXCA pipeline. It is designed for extracting emotion expression features from faces, voices, and speech text in videos.
Note
mexca does not capture experienced emotions, such as “happy” or “sad”, but emotion expressions. Thus, it does not allow users to make direct inferences about the internal emotional states of persons shown in videos. Instead, mexca is intended to study which emotions humans express (more or less intenionally) to the outside world.
The package contains five components that can be used to build the MEXCA pipeline:
FaceExtractor: Detects faces, encodes them into an embedding space, clusters the embeddings to link reoccuring faces, and extracts facial landmarks and action units.
SpeakerIdentifier: Performs speaker diarization, that is, detects speech and speech segments, encodes speakers into an embedding space, and clusters the embeddings. Attempts to answer the question: “Who speaks when?”.
VoiceExtractor: Extracts voice features, such as pitch, associated with emotion expressions.
AudioTranscriber: Transcribes detected speech segments to text.
SentimentExtractor: Predicts sentiment scores for the transcribed text.
Note that these compents can include several of the building blocks in the pipeline as depicted above. For details on the workflow and the pipeline components, see the Features section. The modularity of mexca allows users to customize their pipeline and easily add new components (e.g., to use more recent pretrained models).
Intended Use
To get started and for prototyping, we recommend using the container components in mexca (see Getting Started and Docker).
For longer real-world applications, we recommend the full installation of mexca (pip install mexca[all]) and running the pipeline with GPU support to accelerate processing (see Running mexca on a GPU).
We strongly suggest to apply mexca only to videos of public persons or persons that have given explicit consent to analysis of their emotion expressions. We strongly discourage the use of mexca on private videos or for surveillance purposes. The main intended use case for mexca is (open) research.
Licensing
This software is being developed by the Netherlands eScience Center in collaboration with the Hot Politics Lab, at the University of Amsterdam. Code and data are licensed under the Apache License, version 2.0. This means that Mexca can be used, modified and redistributed for free, even for commercial purposes.